运输层的功能和服务
运输层提供的服务
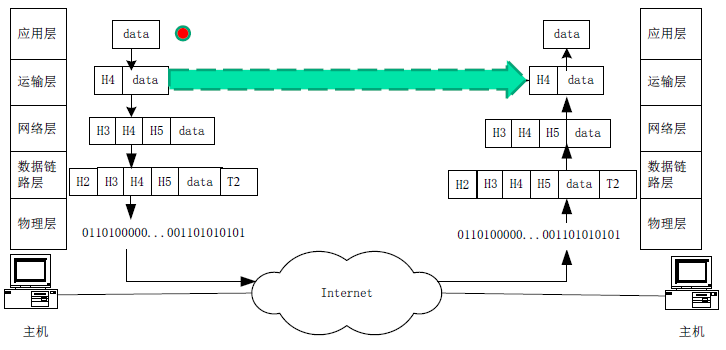
运输层要为应用层建立一个“端到端”的逻辑连接,这个连接是跨网络的。从应用层的角度看,运输层为其提供了一条端到端的数据通道,通过这个通道,数据可以从一方到达另一方。
应用层数据要从一端的应用层到达另一端的应用层,需要使用下层协议的服务,下层协议要把应用层数据从一个进程发送到另一进程,运输层就为应用层提供这样数据传输的服务。运输层为应用层提供了一条端到端的逻辑通道,通过这个通道,应用层报文可以从一个应用进程到达另一个应用进程。所谓端到端的逻辑通道是指从一端的应用进程到达另一端的应用进程,而忽略网络中间节点。
可靠的服务
在可靠的服务中,发送进程的应用层报文交给运输层后,运输层能够保证将数据顺序的、无差错的、无丢失的交给接收方应用进程。运输层在完成这个任务时,需要使用下面层次(网络层)的服务,当网络层不能保证可靠性时,交给网络层的数据可能会丢失,但运输层要采取重传等的方式,对应用层屏蔽这些处理细节,为应用层提供一条无差错、可靠的数据通道。
不可靠的服务
在不可靠的服务中,运输层不能保证数据的有序、可靠的投递,应用层报文可能会丢失、乱序和出错。
运输层的功能
运输层要为应用层提供一条端到端的数据传输通道,主要实现四个功能
- 应用进程寻址
运输层同时要为多个应用进程提供服务,需要确保数据交给正确的应用进程。
- 提供数据的可靠传递
运输层报文段要到达目的地,需要使用下面网络层的服务,当网络层不能提供可靠服务时,运输层报文段就可能丢失、乱序、出错。由于运输层报文段中封装的是应用层报文,所以应用层报文可能也会丢失、乱序、出错。运输层负责检测出这些错误,并且纠正错误。对应用层屏蔽下面网络的不可靠性,为应用层提供一条可靠的数据通道。
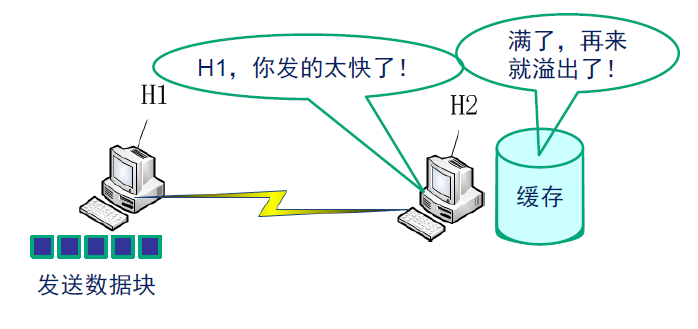
- 流量控制
如果应用进程取走数据的速度小于对方发送的速度,那么缓存很快就会被充满,当再有数据到达时,就会产生溢出,后面的数据就不得不丢弃了。所以,运输层需要有一种机制来控制发送方发送数据的速度,保证接收缓存不溢出,确保接收进程能够及时的处理所有的数据。
- 拥塞控制
运输层要依靠低层的分组交换网络来传递数据,分组交换的核心是存储转发,如果分组网络中拥入大量的数据,加载到网络上的负载超过网络的存储和处理能力,就会出现分组传递时延增加,分组丢失,服务质量下降情况,这种现象称为拥塞。如果不采取有序的检测和控制手段,则拥塞情况就会加重,最终导致网络崩溃,因此运输层需要能够检测拥塞并控制拥塞。
TCP/IP的运输层
TCP/IP体系中,运输层有两个协议:TCP和UDP
UDP只提供应用进程寻址和简单的差错检测功能,它不向应用层提供数据的可靠性传输,但实时性好,效率高。
TCP除了具有应用进程寻址的功能,TCP还能为应用层提供可靠的数据传输服务,能将应用层报文顺序的、无差错的、不丢失的交给对端的应用进程,同时TCP还具有流量控制和拥塞控制的能力。
| 应用 | 应用层协议 | 运输层协议 |
|---|---|---|
| 网页浏览 | HTTP | TCP |
| 文件传输 | FTP | TCP |
| 电子邮件 | SMTP,POP3 | TCP |
| 远程登录 | Telnet | TCP |
| 动态获取IP | DHCP | UDP |
| 域名解析 | DNS | UDP |
| 网络管理 | SNMP | UDP |
| 路由信息交换 | RIP | UDP |
| 简单文件传输 | TFTP | UDP |
| 网络文件系统 | NFS | UDP |
| IP电话 | 专有协议 | UDP |
| 流式多媒体 | 专有协议 | UDP |
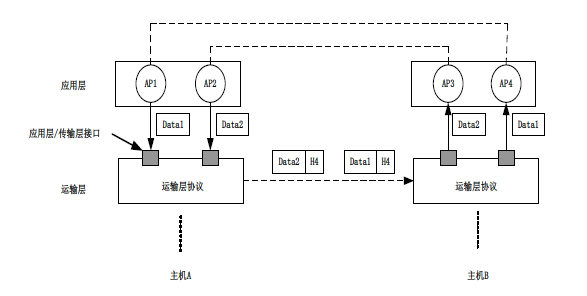
应用进程寻址
- TCP/IP提供端口机制来进行应用进程寻址。
- TCP/IP的运输层通过端口来实现多路复用和多路分解。
- 端口是运输层协议和应用层协议交互的接口,每个端口有本地唯一的端口号。
- 应用进程通过系统调用可以绑定到运输层协议(UDP或TCP)的一个端口上,这样通过端口号就能确定对应的应用进程。
- 端口号占16比特,TCP和UDP端口相互独立。
- 端口号只具有本地意义,不同主机相同端口号的应用进程没有特定联系。
随着各种各样的应用不断增多,应用层协议也会不断增多(例如用户使用FTP协议下载文件的同时也能使用HTTP协议浏览网页)。而在TCP/IP协议体系中命运输出协议只有两个,这样会出现多个应用层协议使用同一个运输层协议的情况。这就涉及到了应用进程寻址的问题。
TCP/IP的运输层提供了多路复用和多路分解来解决应用进程寻址问题。这里的复用是指在发送方不同的应用进程可以使用同一个运输层协议传输数据,而分解是指接收方的运输层在剥去报文的首部后能够把应用层报文交付给正确的目的应用进程。
TCP/IP的运输层通过端口来实现多路复用和多路分解。端口是一种软件结构,每个端口有唯一的端口号,并且有相应的输入和输出缓存。一个应用进程通过系统调用可以绑定到运输层协议(UDO或TCP)的一个端口上,这样通过端口号就能确定对应的应用进程,端口和应用进程是一 一对应的。当应用进程有数据需要运输传递时,它将数据放入对应的端口中;运输层协议会将其取走,并在数据前面添加运输层的首部,在首部里写入发送方的端口号(源端口)和接收方的端口号(目的端口)。这样当对方的运输层协议收到时,就可以根据目的端口号将数据交给正确的应用进程。
| 应用 | 应用层协议 | 运输层协议 | 服务器熟知端口 |
|---|---|---|---|
| 网页浏览 | HTTP | TCP | 80 |
| 文件传输 | FTP | TCP | 21 |
| 电子邮件 | SMTP,POP3 | TCP | 25,110 |
| 远程登录 | Telnet | TCP | 23 |
| 动态获取IP | DHCP | UDP | 67 |
| 域名解析 | DNS | UDP | 53 |
| 网络管理 | SNMP | UDP | 161 |
当客户端向这些服务器发起通信时,需要使用的运输层协议和服务其端口都是已知的,对于客户端进程,操作系统通常会随机给他分配一个大于1024的端口号,由于服务器端口是已知的,客户端可以首先向服务器发送给信息,服务器收到信息后,根据运输层首部中的源端口,可以知道客户端进程的端口号,这样也就可以向客户端发送数据了。
UDP
用户数据协议(User Datagram Protocol)是TCP/IP协议体系中运输层协议之一,UDP协议只是提供应用进程寻址和简单的差错检测,并不提供其他功能。UDP接收应用层报文,加上UDP首部后封装成UDP数据报。
UDP协议的特点
- UDP是无连接的,即发送数据之前不需要建立连接
UDP发送数据之前不需要与对端建立连接(当然发送数据结束时也没有连接可释放),因此减少了开销和发送数据之前的时延。数据被封装成UDP数据报后直接发送,每个数据报都是独立的,双方的UDP都不去记录发送数据报和接收数据报的情况。UDP的工作方式与现实生活中的寄信和类似。
- UDP使用尽力而为的服务方式,也就是不能保证可靠的传输
UDP不提供可靠的数据传输服务,UDP数据报在传输过程中可能会出现丢失、重复、乱序的情况,但UDP并不纠正这错误,而是直接将负载数据上交应用层。UDP提供了差错检测的功能(可选),一旦检测出UDP数据报出现错误,就将其丢弃,不向应用层传递。
- UDP是高效的传输协议,UDP对应用层交下来的报文,既不合并,也不拆分,这可使应用层的数据被迅速、及时的发送出去。
UDP在收到上层应用报文后,既不合并也不拆分,添加首部后就直接发送,这使应用层的数据可以被迅速、及时地发送出去。在收到UDP报文后,如果没有选差错检测,UDP能将数据立即上传到应用层。因此UDP的效率比较高,适合于对实时性要求高,但能够容忍部分数据丢失的应用,如视频会议、在线音频等。在数据传输可靠性比较高的网络里(如局域网),UDP往往会工作得很好。
- UDP没有拥塞控制和流量控制
网络出现的拥塞不会使源主机的发送速率降低。很多的实时应用(如IP电话、实时视频会议等)要求源主机以恒定的速率发送数据,并且允许在网络发生拥塞时丢失一些数据,但却不允许数据又太大的时延,UDP正好适合这种要求。
| 应用 | 应用层协议 | 运输层协议 |
|---|---|---|
| 动态获取IP | DHCP | UDP |
| 域名解析 | DNS | UDP |
| 网络管理 | SNMP | UDP |
| 路由信息交换 | RIP | UDP |
| 简单文件传输 | TFTP | UDP |
| 网络文件系统 | NFS | UDP |
| IP电话 | 专有协议 | UDP |
| 流式多媒体 | 专有协议 | UD |
UDP对应用层交下来的报文,不合并,不拆分,封装后直接发送
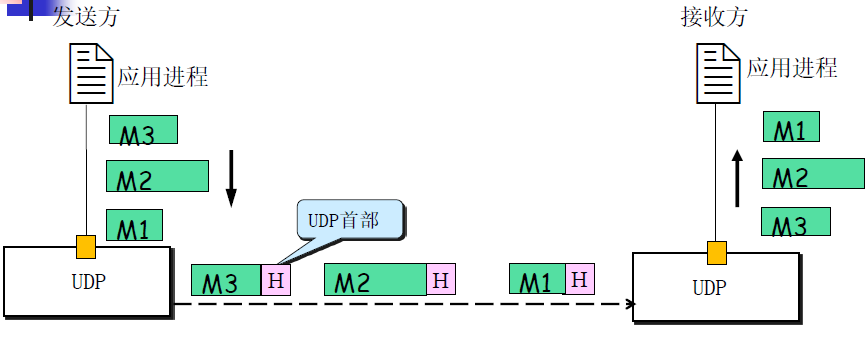
UDP数据报
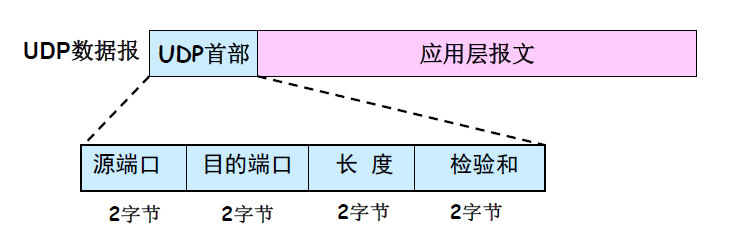
UDP数据报由UDP首部和其封装的应用层数据组成,是UDP协议的传输单元。UDP的首部比较简单,只有8个字节。UDP首部中的8个字节由4个字段组成,每个字段的长度都是2个字节。
UDP首部封装应用层报文,生成UDP数据报
- 源端口:发送数据应用进程的端口号,在需要对方回复选用,不需要时可用全0。
- 目的端口:接收数据应用进程的端口号,利用源端口和目的端口可以实现多路复用和多路分解。
- 长度:UDP首部和应用层报文的总长度,单位是字节,理论上UDP数据报的长度可以达到2^16字节,但实际上受下面数据链路层的限制,UDP数据报的长度要远远小于这个值。
- 检验和:检测首部和应用层报文的错误,有错误就丢弃UDP数据报。
例子
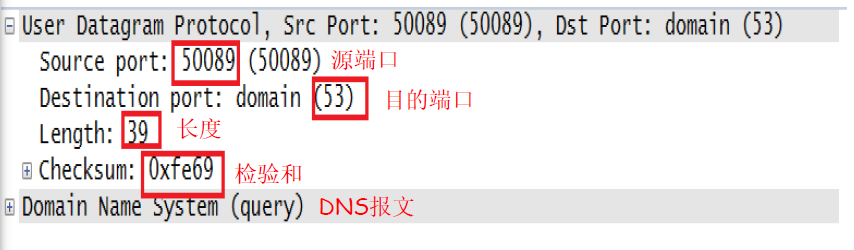
UDP校验和
UDP提供首部检验和字段来检测UDP数据报在传输过程中的错误,一旦检测出错误,UDP会丢弃收到UDP数据报。UDP计算检验和时,需要添加一个伪首部一起进行计算,计算校验和的范围包括伪首部,UDP首部和数据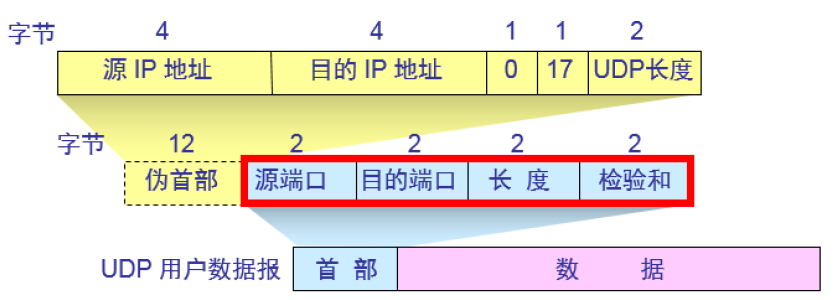
UDP的差错检测
从发送发到达目的地,UDP数据报可能会经过许多条链路,在这些链路上可能会出现差错,而有些链路可能不提供差错检测的功能。同时在转发IP报文时,在内存中可能也会产生比特差错,从而影响到IP报文中所封装的UDP数据报。因此,提供发送方和接收方之间端到端的差错检测是必要的。UDP提供首部检验和字段来检测UDP数据报在传输过程中的错误。一旦检测出错误,UDP会丢弃出错的UDP数据报。但UDP的校验是可选的,当首部校验和为0时,表示没有校验。
UDP用户数据报首部中校验和的计算方法有些特殊,在计算时要在UDP用户数据之前增加12个字节的伪首部。“伪首部”只是在计算检验时,临时添加在UDP用户数据报前面,得到一个临时的UDP用户数据报。伪首部既不向下传送也不向上递交,而仅仅是为了计算检验和。伪首部和UDP数据报作为一个整体一起来计算校验和,伪首部中含有源IP地址和目的IP地址,这样可以检测出数据报被送到错误目的地的情况。因为校验和字段包含在UDP报文首部内,所以在计算时,校验和字段会先置0并参与计算,计算完毕后再将结果填入校验和字段。伪首部的17是分配给UDP的协议编号(TCP的协议编号是6),UDP长度是指UDP报文的长度(包括首部和数据)。
发送方计算校验和过程
- 在校验和字段放入0(为了完成计算过程)
- 以16比特为一个单位,把伪首部及UDP用户数据报分成许多个16位字符。如果UDP用户数据报的数据部分不是偶数个字节,则要添加一个全0的字节(但此字节不发送)
- 按照二进制反码算数运算求和来计算这些16位字的和
- 将第三步的结果按位取反,即得到校验和,写入校验和字段,去掉伪首部
在接收方,运输层收到UDP数据报后,添加伪首部(与发送发添加的伪首部相同)进行校验。按二进制反码求这些16位字的和。当无差错时,其结果应全为1,否则就表明有差错出现,接收方就丢弃这个UDP用户数据报。
UDP差错检测是可选的
- 如果不需要校验,发送方会将校验和字段置为全,接收方看到校验和全为,不对数据进行检验
- 如果需要检验,发送方在校验和字段写入非零的校验和,接收方收到后,要进行校验
TCP
TCP(传输控制协议)是专门为了在不可靠的互联网络中提供一个可靠的端到端的通信而设计的,是TCP/IP协议体系中运输层的重要协议。TCP为应用层提供面向连接的、可靠的数据传递服务。发送方应用进程将数据交给TCP,TCP保证将这些数据有序地、无差错地、完整地送达目的应用进程。TCP为应用进程构建了一个可靠的比特流管道,发送发应用进程报文从一端流入,无差错地、完整地从另一端流出,交给接收方应用进程。因此TCP适用于对数据可靠性有要求的应用。
| 应用 | 应用层协议 | 运输层协议 |
|---|---|---|
| 网页浏览 | HTTP | TCP |
| 文件传输 | FTP | TCP |
| 电子邮件 | SMTP,POP3 | TCP |
| 远程登录 | Telnet | TCP |
TCP协议的最主要特点
- TCP是面向连接的运输层协议
TCP协议在运输层应用层报文前,两端的TCP协议必须建立一个TCP连接,在传送数据完毕后,再释放已经建立的TCP连接。这就好像应用进程的通信是在“打电话”,通话前要先拨号接通,通话结束后要挂机。每一条TCP连接只能有两个端点,每一条TCP连接只能是点对点的通信。
- TCP提供可靠的数据传输服务
TCP在传输数据时要使用下面层次的服务。如果下层网络是不可靠的,TCP要屏蔽掉下层网络的不可靠性,为上面的应用层提供一条可靠的数据传输通道。
- TCP提供流量控制
TCP能够控制进程发送数据的速率,保证另一端不被大量的数据”淹没“而出现溢出。
- TCP提供拥塞控制
当网络出现拥塞的时候,TCP能够减小向网络注入数据的速率和数量,缓解拥塞。
- TCP提供全双工通信
TCP提供双向的数据传输服务,TCP允许通信双方的应用进程同时发送数据,TCP连接的两端都设有发送缓存和接收缓存,用来临时存放双向通信的数据。在发送时,应用进程在把报文传送给TCP后,就可以做字节的事,而TCP在合适的时候把数据发送出去,在接收时,TCP把收到的报文放入缓存,上层的应用进程在合适的时候读取。
- TCP是面向字节流的
TCP中的“流是指流入到进程或从进程流出的字节序列。“面向字节流”的含义是:虽然应用程序和TCP的交互是一次一个数据块(数据块的大小可能不等),但是TCP把应用程序交下来的所有数据块看成是一连串的无结构的字节流, TCP并不知道所传输的字节流的含义。TCP要对传输的每个字节都进行编号,封装在TCP报文段中传递,应用进程收到的字节流和对方应用进程发出的字节流完全一样。
TCP报文段
TCP在应用层数据前添加TCP首部,形成TCP报文段,TCP报文段是TCP的传输单元。一个TCP报文段分为首部和数据两部分,TCP协议的主要功能都体现在首部的各个字段中。
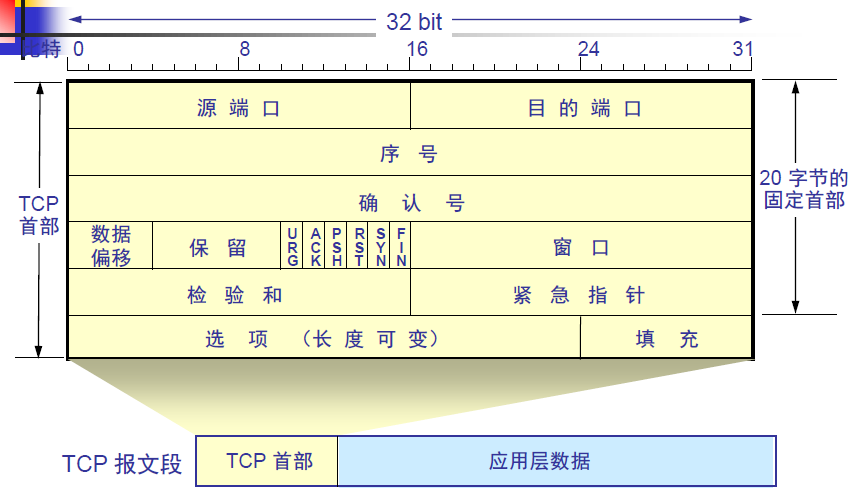
- 源端口和目的端口字段各占两个字节,源端口是发送方的端口号,目的端口是接收方的端口号
- 序号字段(seq),占四个字节,TCP连接种传送的数据流种的每一个字节都编上一个序号,序号字段的值则指的是本报文段所发送的数据的第一个字节在整个字节流种的编号
- 确认号字段(ack),占四个字节,是期望收到对方的下一个报文的数据的第一个字节的编号,期望实际上是隐含确认,ack n表示编号n以前的字节都收到
- 数据偏移,占四bit,它指出TCP报文段的实际起始处距离TCP报文段的起始处有多远。数据偏移的单位不是字节而是三十二bit字(四字节为计算单位)
- 保留字段,占六bit,保留为今后使用,但目前应置为零
- 标准字段,占6比特,每个比特都代表特定的含义,当其值为1时称为置位
- 紧急比特URG,当URG=1时,表明紧急指针字段有效。它告诉系统此报文段中有紧急数据,应当尽快传送(相当于优先级的数据)
- 确认比特ACK,只有当ACK=1时确认号字段才有效。当ACK=0时,确认号无效
- 推送比特PSH(Push),接收TCP收到推送比特置1的报文段,就尽快地交付给接收应用进程,而不再等到整个缓存都填满了再向上交付
- 复位比特RST(Reset),当RST=1时,表明TCP连接中出现严重差错(如由于主机崩溃或其他原因),必须释放连接,然后再重新建立运输连接
- 同步比特SYN,同步比特SYN置为1,就表示这时一个连接请求或连接接收报文
- 终止比特Fin(Final),用来释放一个连接,当FIN=1时,表明此报文段的发送端的数据已发送完毕,并要求释放运输连接
- 窗口字段,占两个字节。窗口字段用来控制对方发送的数据量,单位为字节,TCP连接的一段根据设置的缓存空间大小确定字节的接收窗口大小,然后通知对方以确定对方的发送窗口的上限
- 检验和,占两个字节,检验和字段检验的范围包括首部和数据这两部分,在计算检验和时,要在TCP报文段的前面加上十二字节的伪首部
- 紧急指针字段,占16bit,紧急指针指出在本报文段中紧急数据的最后一个字节的序号
- 选项字段,长度可变,TCP只规定了一种选项,即最大报文段长度MSS(Maximum Segment Size),MSS告诉对方TCP:“我的缓存所能接收的报文段的数据字段的最大长度是MSS个字节。”
- 填充字段,这是为了使整个首部长度是四个字节的整数倍
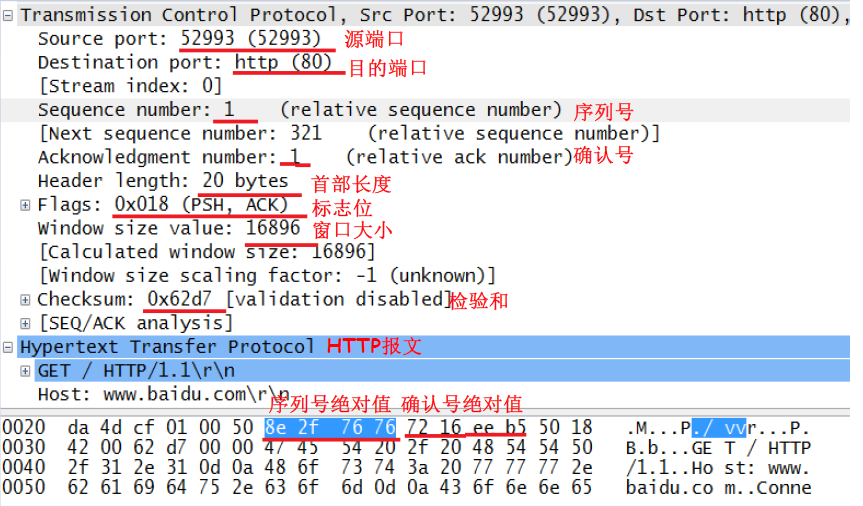
TCP报文段例子
TCP数据传输过程
三个阶段依次是建立连接,数据传输和关闭连接。
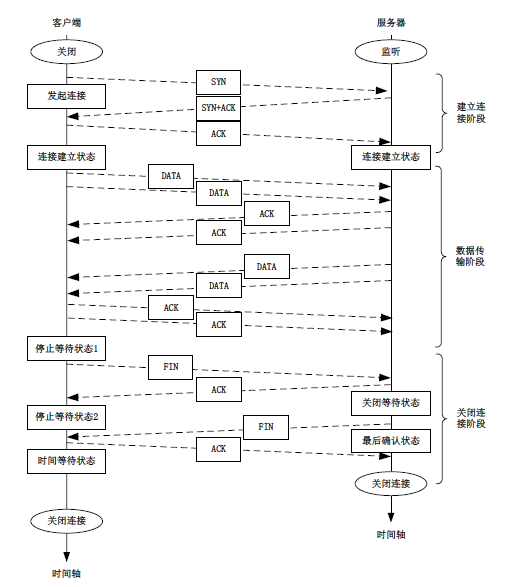
建立连接:目的是使通信双方在开始传输数据前建立联系,使双方都确定对方愿意与之通信;同时在建立连接的过程中还要相互传递和协商一些必要的参数(如发送字节的起始编号、窗口大小等),为后面的数据传输打下基础。
数据传输:连接建立后,开始传输数据,TCP的数据传输是双向的,在数据传输阶段TCP要纠正数据传输中的丢失、错误、乱序等问题,并要进行流量控制和拥塞控制。
关闭连接:在两个通信的应用进程之间的数据传输完毕后,就要关闭它们之间的连接,释放资源。
连接管理
TCP连接不是实际的物理连接,是在通信的两个端点建立的虚拟形式上的连接。
TCP为应用层提供面向连接(connection-oriented)的服务,在传递应用层数据前,TCP要首先为两个应用进程之间建立一个连接。连接建立后,TCP才能传输应用层报文,应用层数据传输完毕,需要关闭连接。
TCP连接是为通信的两个应用进程建立的虚拟形式上的连接,由操作系统软件实现。TCP连接的端点称为套接字(socket),(IP地址:端口号)可以用来表示一个套接字。
一个TCP连接可以用连接两端的套接字来表示
- (IP地址1:端口号1)———————————(IP地址2:端口号2)
- (192.16.23.5:1035)———————————(10.153.16.54:80)
TCP连接通常是由客户端发起建立的,建立连接的过程称为“三次握手”(three-way handshake)
为什么要建立连接?
- TCP需要确认双方应用进程都准备就绪
- TCP需要为连接分配输入缓冲区、输出缓冲区;初始化TCP连接的控制变量(如序列号、接收窗口大小等);交换连接控制参数
TCP建立连接是要为后续的数据传输做好准备
TCP连接的建立采用客户/服务器方式。主动发起连接建立的应用进程叫做客户(client)而被动等待连接建立的应用进程叫做服务器(sever)。最初两端的TCP连接都处于关闭状态(closed)。三次握手的过程首先由客户端发起,客户端主动打开连接,服务器端收到连接请求后被动打开连接。
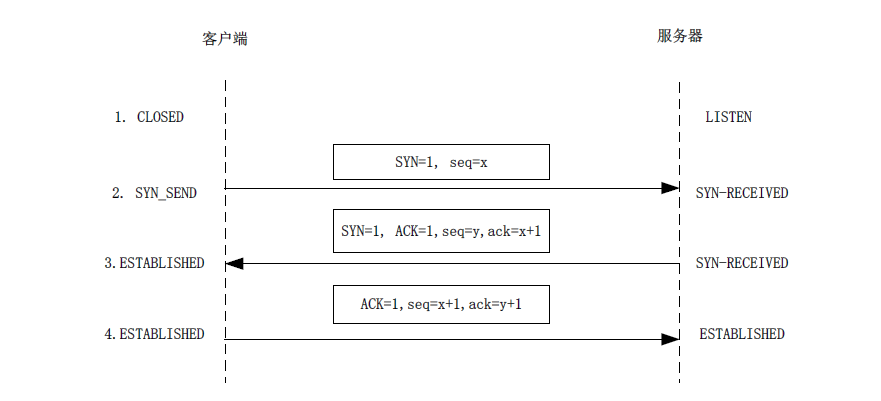
三次握手的过程
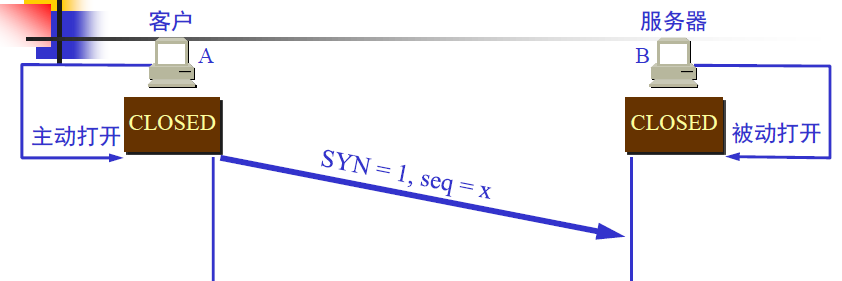
第一次握手
根据客户—服务器模型,通信首先由客户端发起。第一个TCP报文段由客户端发出,这报文端只有TCP首部,没有封装应用层报文(因为连接尚未建立,不能发送数据)。标志位SYN置1,表示客户端想和服务器建立连接。另外,客户端还要告诉服务器它所发送字节流的起始编号,这个编号对于TCP提供可靠性是一个重要的参数,在首部的序号(seq)字段中给出。起始编号是随机的,这里用x代替。
A的TCP向B发出连接请求报文段,其首部中的同步位SYN=1,并选择序号seq=x,表明传送数据时的第一个数据字节的序号是x。
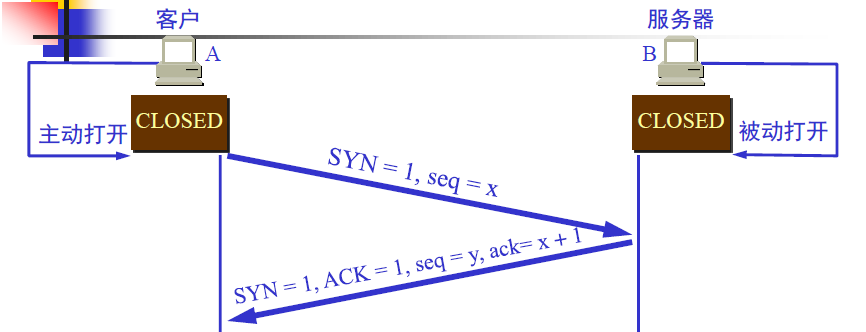
第二次握手
服务器的TCP收到客户端的TCP报文后会回应一个TCP报文段。标志SYN和ACK均置1.序号字段的值为y,表示服务器告诉客户端字节发送的字节流起始编号为y(因为通信是双向的,服务器也会给客户端发送数据)。另外,将确认号(ack)字段的值置为x+1,表示对客户端上一个TCP报文的确认。注意这里的确认号是x+1,而不是x,隐含的意思是告诉客户端收到了编号为x的报文,现在期望客户端发送编号为x+1的报文。
B的TCP收到连接请求报文段后,如同意则发回确认。B在确认报文段中应使SYN=1,使ACK=1,去确认号ack=x+1,自己选择的序号seq=y。
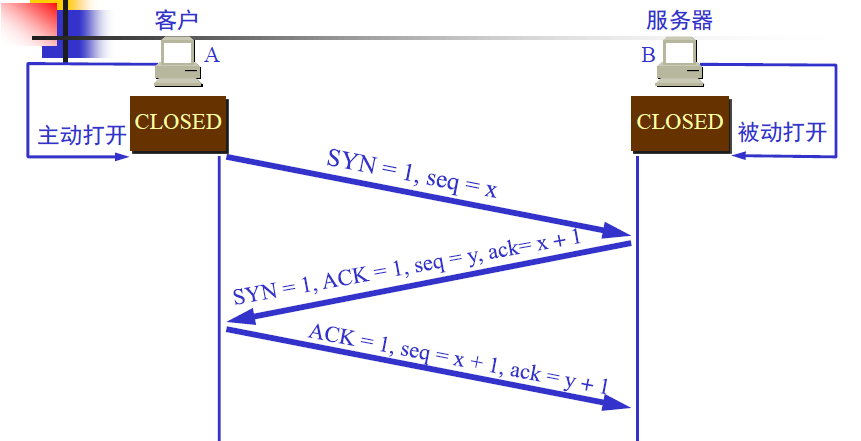
第三次握手
客户端的TCP收到服务器的应答后,需要再发送一个TCP报文。其中,标志ACK置1,序号seq的值为x+1(正是服务器TCP所期望的),确认号ack的值置为y+1表示服务器编号为y的报文的确认。
A收到此报文段后向B给出确认,其ACK=1,确认号ack=y+1。A的TCP通知上层应用进程,连接已经建立。B的TCP收到主机A的确认后,也通知其上层应用进程:TCP连接已经建立。
在三次握手建立连接的过程中,双方通常还会在TCP报文段的选项字段(Option)中向对方通告自己的最大报文段长度,称为MSS(Maximum Segment Size)。MSS描述的是本方TCP段中数据部分可以承载的最大字节数。
三次握手建立TCP连接的各种状态
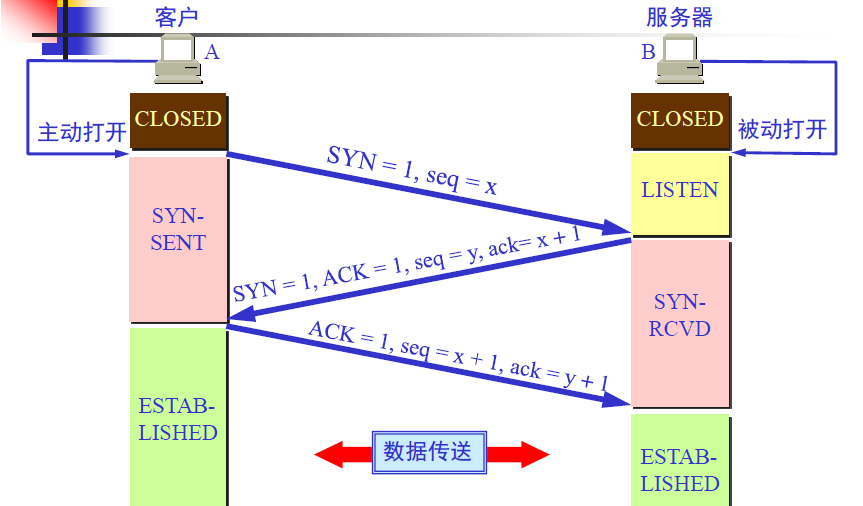
TCP三次握手报文
客户端—>服务器:SYN=1,seq=x
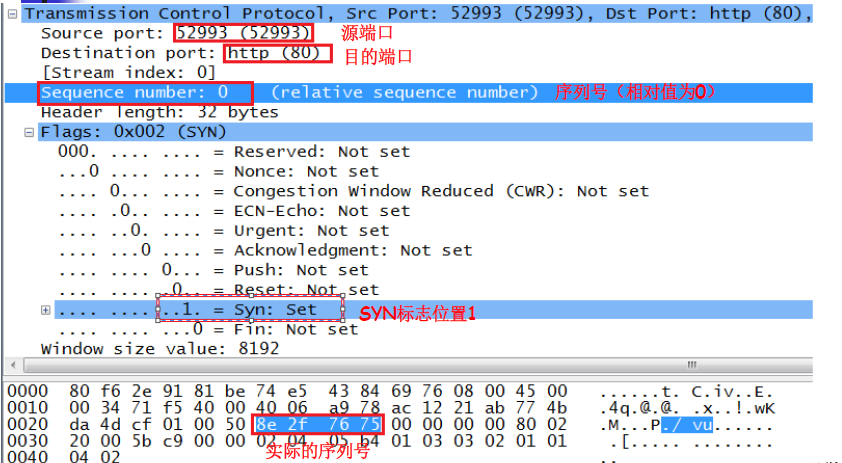
服务器—>客户端:SYN=1,ACK=1,seq=y,ack=x+1
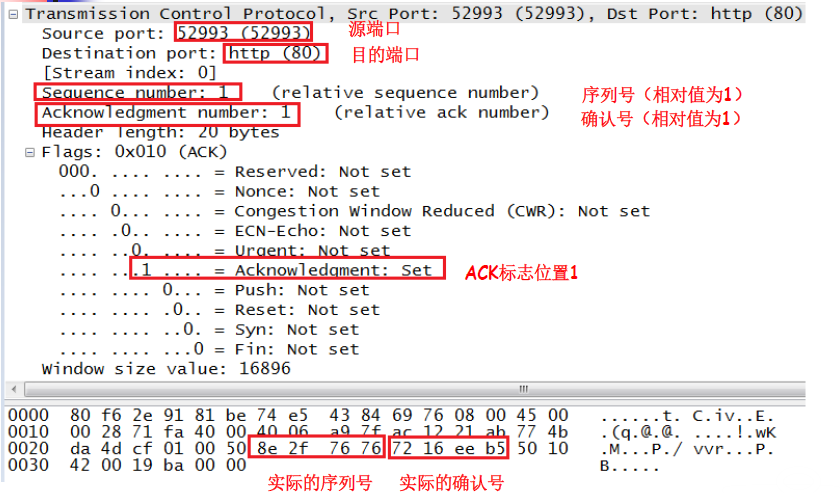
服务器—>客户端:ACK=1,seq=x+1,ack=y+1
关闭连接
在两个通信的应用进程之间的数据传输完毕后,就要关闭它们之间的连接。需要四步,客户端和服务器都可以提出关闭连接的请求。
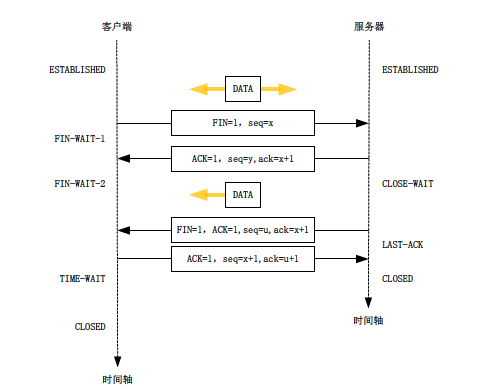
- 当客户端应用进程关闭时,客户端的TCP会向服务器发出一个特殊的TCP报文段,其中FIN标为位置为1,用来告诉服务器:客户端的数据发送完毕,要关闭连接。
- 服务器的TCP收到这个报文段后,会通知服务器进程,同时发送一个确认的TCP报文段,在这个报文段中ACK标志位置为1.到此为止,从客户端到服务器这个方向上的连接就释放了。因为TCP提供的是双向的数据通信,所以这时只关闭了从客户端到服务器,这一个方向上的连接,TCP连接处于半关闭(half-close)状态。
- 服务器还需要关闭另一个方向的连接。于是,服务器发出一个TCP报文段,在这个报文段中FIN标志位置为1,通知客户端关闭连接。
- 客户端的TCP收到后,通知客户端进程,同时向服务器发送确认的TCP报文段,此时连接就全部关闭了。双方的TCP都会释放掉这个连接所占的全部资源。
时间等待计时器
关闭连接中,在第四步完成之后,TCP连接并没有真正释放掉,而是启动一个时间等待计时器(TIME-WAIT timer),使客户端进入“TIME-WAIT”状态。
在TIME-WAIT timer到时候,才真正关闭客户端连接,释放资源。
时间等待计时器设置的时长是两个最长报文寿命(Maximum Segment Lifetime,MSL),客户端是在等待2MSL时间后,才真正关闭客户端的连接,释放资源。
为什么必须等待2MSL的时间?
- 为了保证A发送的最后一个ACK报文段能够到达B
- 保证本地连接持续时间内所产生的所以文段都从网络中消失
保活定时器
一个TCP连接建立后,可能会长时间处于空闲状态,没有任何数据交互。造成这种情况的原因是多种多样的。也许双方确实没有数据交换,也许是因为客户端崩溃了(死机或其他原因)。但服务器并不知道这个情况,他会长时间为这个连接保留缓存和其他资源。因此服务器需要知道客户端是否已经关闭或是重启,需要确认是否有必要继续保留这个连接。服务器通过设置“保活定时器(keepalive timer)”来达到这个目的。保活定时器的时间一般设为两个小手,如果服务器在两个小时内收到客户端的信息,那么定时器就复位,重新计时;如果两个小时内没有收到任何数据,那么服务器TCP就会给客户端发送一个探测报文。
此时客户端可能处于以下四个状态。
- 客户端依然活跃,并且收到服务器的探测报文。此时客户端的TCP便发出响应报文,使服务器知道自己仍然处于活动状态。服务器的TCP会将保活定时器复位,保持这个连接。
- 客户端已经崩溃,并且已经关机。此时服务器的TCP不会收到任何响应。然后服务器TCP每隔75s发送一个探测报文,如果发送10个探测报文后仍然没有回应,那么服务器就关闭连接,释放相应的资源。
- 客户端已经重启,这时客户端的TCP不会保留原来的连接信息。当收到服务器的探测报文后,客户端TCP会发送一个复位(RST)的响应,服务器收到后便会关闭连接。
- 客户端依然活跃,但是始终都无法收到服务器的探测报文(可能是由于网络拥塞造成的)。这种情况同第二种类似,服务器收不到响应,也会关闭连接。
数据的可靠性传输
运输层TCP的一个重要任务就是能够把发送方数据可靠地传给接收方。在TCP通信过程中,一旦建立连接后,客户端的应用进程和服务器的应用进程就可以使用这个连接进行数据传输了,应用层将应用层报文交给TCP,TCP添加TCP首部形成TCP报文段,TCP报文段要发送到对方的TCP,需要使用IP协议的服务,TCP报文段要被封装成IP报文发送到目的地主机。在传输过程中,TCP会遇到以下问题。
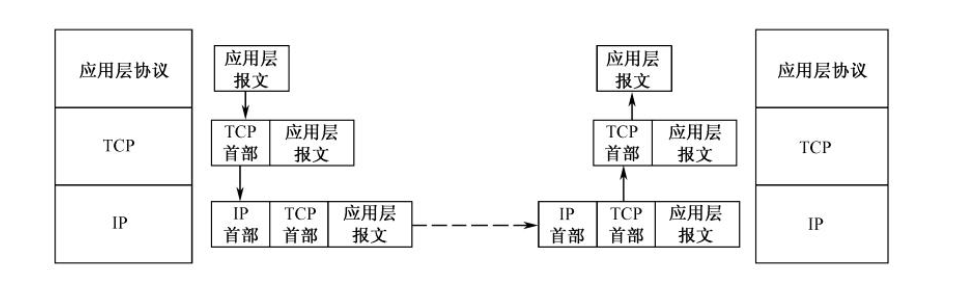
- 数据丢失问题
- 数据乱序问题
- 重复数据问题
- 数据错误问题
TCP面临面临着数据在的丢失、乱序、重复和出错问题。TCP要对应用层屏蔽并纠正这些错误,在一个不可靠的IP协议上,为应用层构建一个可靠的数据传输通道。
可靠传输原理
为了给应用层提供可靠数据传输服务,TCP采取了以下措施
- 对发送的每个字节进行编号
- 对收到的字节进行确认
- 设定重传定时器
可靠传输实现
基于以上的三个措施,TCP采取了带有定时器的确认和重传机制实现了数据的可靠性。
- TCP报文段丢失
如发送方共发送三个报文段,前两个都正确到达了,第三个报文段中途丢失了。因此,发送方在定时器时间内没有收到对第三个报文的确认。于是,发送方重传第三个报文段,这次接收方收到了,并发送会确认报文。
- TCP报文段里的数据出错
每收到一个TCP报文段,接收端的TCP首先要验证报文段首部的校验和。TCP首部校验和的计算过程与UDP类似,也要加上一个伪首部。如果报文校验有错,直接将其丢弃,因此也不会给对方发送任何确认报文。对于发送方而言,相当于报文段丢失了。这样当发送发的定时器超时后,发送方便会重传这个TCP报文段。
- 报文段的重复问题
可以考虑这样一种情况:接收方收到正确的报文段,于是发送确认报文,但是确认报文在中途丢失了;于是,发送方没有收到确认报文,定时器超时后又会重传,这样接收方就会收到重复的报文段。对于重置的报文段,接收方的处理是直接将其丢弃,同时发送确认报文。
- TCP报文段的乱序问题
TCP报文段是封装在IP报文中传递的,而IP网络采用数据报技术,IP报文不能保证顺序地到达,所有TCP报文段可能会乱序到达。例如,在收到字节序号为1400的数据后,接着收到字节序号为8011200的数据,缺少序号为401800的数据。此时TCP通常会选择缓存这些乱序的报文,等序号为401800的数据到达后,将其排序再上传给应用进程。
- 快速上传
超时重传机制能够重传丢失的数据包,但有时超时计时器的时间设定会比较长,这样会导致发送方要在很长的时间后才能重传数据,从而增加端到端之间的时延。TCP通过发现冗余确认来较快的检测丢包的情况,从而实现快速重传。
重传定时器
在确认和重传的机制中,重传定时器用来对报文确认与等待重传时间的计时。在发送一个TCP报文段后,就会启动定时器。如果在定时器截止时间之前收到确认报文,就撤销这个定时器。如果定时器时间到了,确认报文还没有收到,就重传该报文并将重新设置定时器。
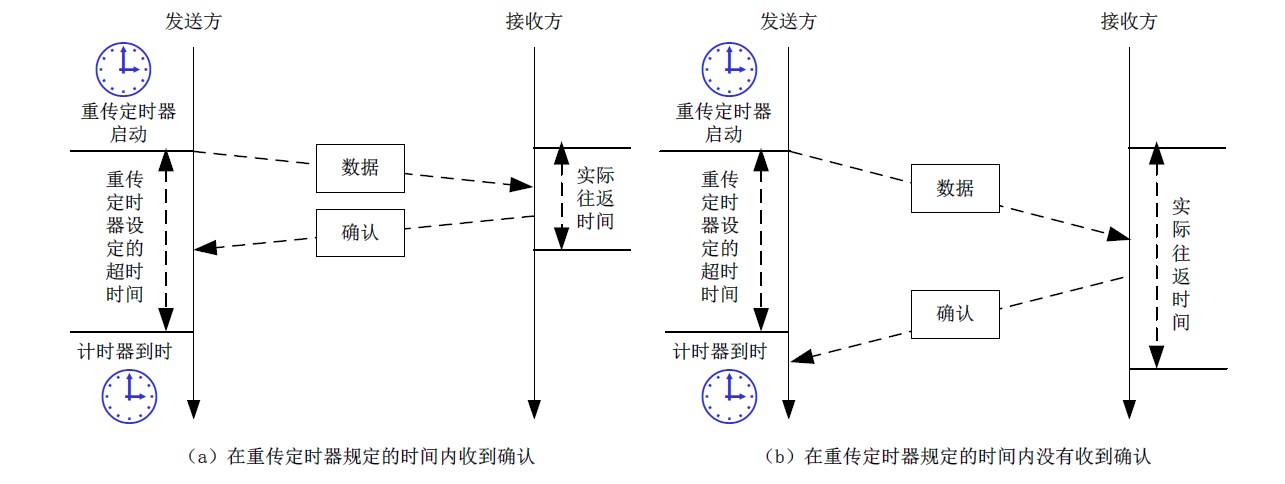
重传定时器的原理比较简单,但具体实现上有两个问题需要考虑:
- 重传定时器的时间
设定重传定时器适当的时间值对于TCP协议是很重要的。如果值设置的过低,可恩能出现被接收方正确接收的报文,再次被重复传输的问题。如果设置的值过高,可能造成报文已经丢失,而发送方处于长时间等待的问题,降低了传输效率。由于互联网在不同时间段的用户数量、流量与传输延迟变化也很大,因此重传定时器的时间设置应该是一个动态的值,根据网络状况的不同而变化。
- 重传定时器的管理
不同的连接应该使用不同的重传定时器,一个主机同时与其他两个主机建立两条TCP连接,那么TCP就需要分别为每个TCP连接启动单独的重传计时器,不可能对不同的TCP连接使用同一个重传计时器。对于同一个连接,是否要为每个发送的TCP报文段都启动一个定时器?一个报文段一个定时器在原理上比较简单,但实现和管理上会比较复杂。如果一个连接只使用一个定时器,合适使用定时器,定时器超时要如何处理?
重传定时器计算
重传定时器的时间定义为TRO(Retransmission Timeout)。RTO应该比连接上的往返时间长一些。
RTT(Round-Trip Time):RTT代表一个TCP报文段从发出后到收到确认报文的往返时间。TCP需要不断测量RTT的样本值
SRTT(Smoothed Round-Trip Time):因为网络的状况经常发生变化,所有RTT的值不是固定的,是动态变化的,这里使用SRTT代表RTT的均值。TCP需要不断对RTT值进行测量,获取样本值,来动态调整SRTT。
RTTVAR(Round-Trip Time Variation):表示本次测量的RTT样本值与SRTT的偏差。

由于RTT样本会随着网络的状况发生变化,所以SRTT和RTTVAR也是一个变化值。因此RTO也是动态变化值。RTTVAR反映的是当前的RTT样本和SRTT估计之间的偏差,偏差越大,RTO就越大,反之就越小。这样才能比较正常的反映网络的真是状况,不会因为时间设置过短,造成不必要的重传;也不会因为时间设置过长,而给应用层带来很大的数据时延。
样本值的测量
理论上,TCP应该为每一个发出的报文段测量RTT样本,但实际上多数的TCP实现每次仅为一个报文段测量样本RTT。当发生一个报文段时,如果定时器已经被使用,该报文段不计时。
并且对于重传的报文,TCP不计算其样本RTT。因为对于重传的TCP报文段,如果收到确认,无法判定是对前一个报文段的确认还是对重传报文段的确认,所以TCP仅为传输一次的报文测量样本的RTT值。
定时器管理
理论上假定为每个传输的报文段都设置定时器,但是定时器管理会有很大的开销,所以RFC2988推荐使用单一的重传定时器。定时器启动遵循以下原则
当要有数据(包括重传)发生时,如果定时器没有启动,就启动定时器
当所有的数据都被确认,关闭定时器
当收到确认ACK后,重新启动定时器
当定时器超时时,作以下处理:
重传未被确认的报文
设置RTO<—RTO*2
重启定时器
具体算法

流量控制
在建立连接时,TCP连接的每一端都会为这个连接分配一定数量的接收缓存,当收到正确的应用层报文后,就将其放入缓存,等待应用进程取走。如果发送进程发送数据的速度超过了接收进程取走数据的速度,那么接收缓存很快就会被充满,最后溢出,导致数据丢失。所以,需要一种机制来控制发送进程发送数据的速度,保证接收缓存不会溢出,这种机制称为流量控制。
滑动窗口机制
流量控制的基本原理是接收方告诉发送方还可以发送多少字节的数据,由接收方来控制发送方发送数据量,这样接收缓存就不会溢出了。
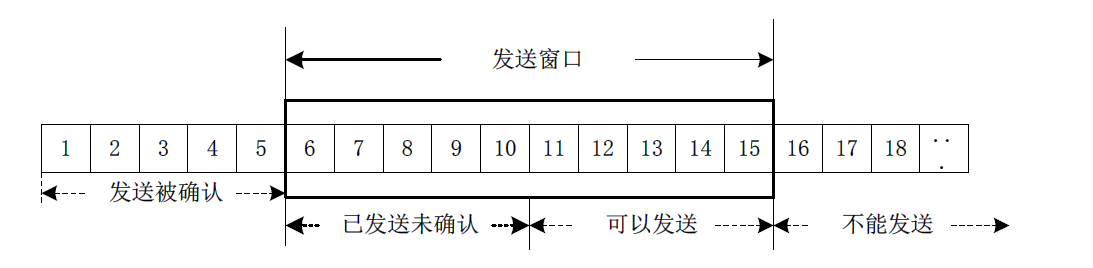
发送窗口左侧边界的初始值在建立连接时确定,由TCP要发送的第一个字节编号确定。在收到对方确认后,发送窗口左边界向右移,移动的位置取决于对方TCP报文段中确认号ack字段的值。发送窗口的大小取决于收到对方TCP报文段中的窗口大小字段的值,窗口大小win字段的值反映了对方接收缓存的空余空间。窗口大小的初始值由建立连接时对方TCP报文段的窗口大小字段通告确定。
当收到正确数据后,数据放入缓存,接收缓存容量变小。新的确认号和新的窗口大小会放在确认报文段的TCP首部中发送给对方,对方的发送窗口会据此向右移动,并调整大小,从而将后续的字节不断发送出去。在整个通信过程中,TCP接收缓存的大小是在不断变化的,通信双方不断将字节当前接收缓存大小通告给对方,从而达到流量控制的目的。
流量控制中的两个问题
- 零窗口通告的问题
接收方窗口原先为0,发送方不能发送数据。后来接收方窗口增大,但没有通知发送方,双方死锁。
解决方案:坚持定时器
- 糊涂窗口症状
接收方窗口每次只增大1,通告给发送方,发送方每次只能发送1字节数据,效率低。
解决方案:暂不发送窗口更新,等缓存有了合适的空余(如一半空闲),在发送窗口更新。
拥塞控制
拥塞的产生:大量的数据涌入网络时,超出了网络的容纳和处理能力,网络中的部分路由器就会因为过载而被迫丢弃一些分组,产生“拥塞”。甚至使整个网络陷入瘫痪。
TCP拥塞控制的主要任务是按照中间网络的接收和处理能力,来决定向网络中发送数据的大小和速度,尽力避免拥塞的产生。
流量控制关注接收端处理能力,拥塞控制关注网络传输能力。
如何判断产生拥塞
网络中的路由器没有直接的办法通知TCP产生的拥塞,TCP需要自己去“感知”网络拥塞状况。
当TCP检测到数据包丢失时,就认为产生了拥塞。
- 重传定时器超时:发生了比较严重的拥塞
- 收到重复确认:出现了一定程度的拥塞
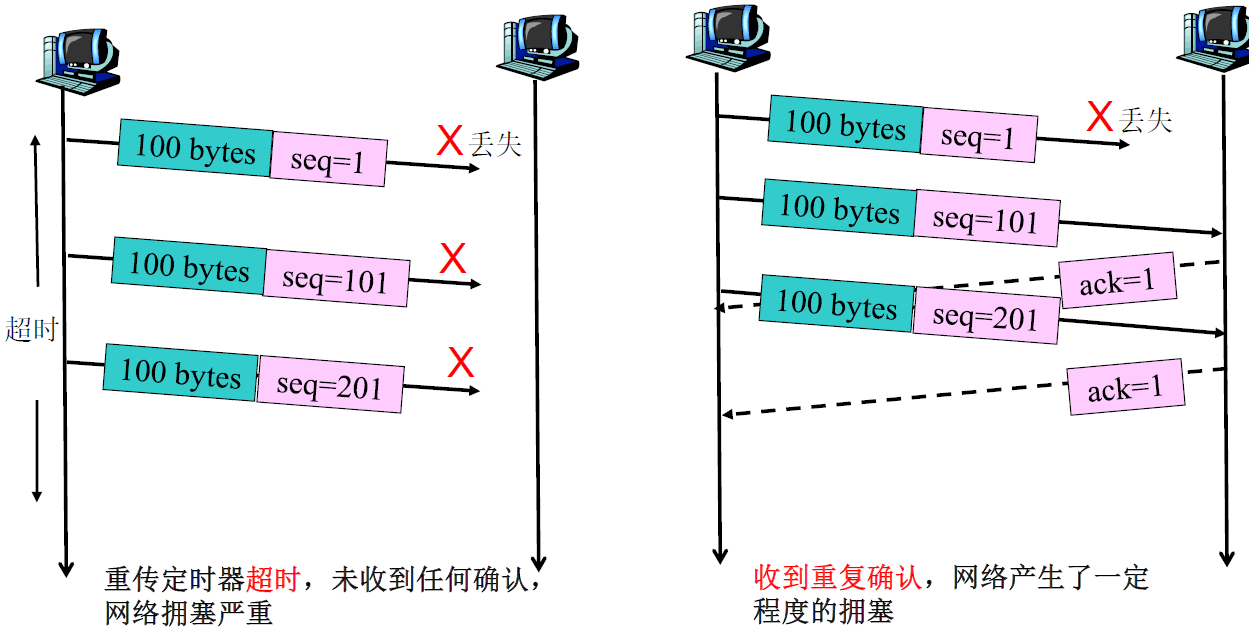
如何处理拥塞
TCP处理拥塞时,使用了两个控制变量和两个算法。两个控制变量是拥塞窗口和门限值。两个算法是慢启动算法和拥塞避免算法。
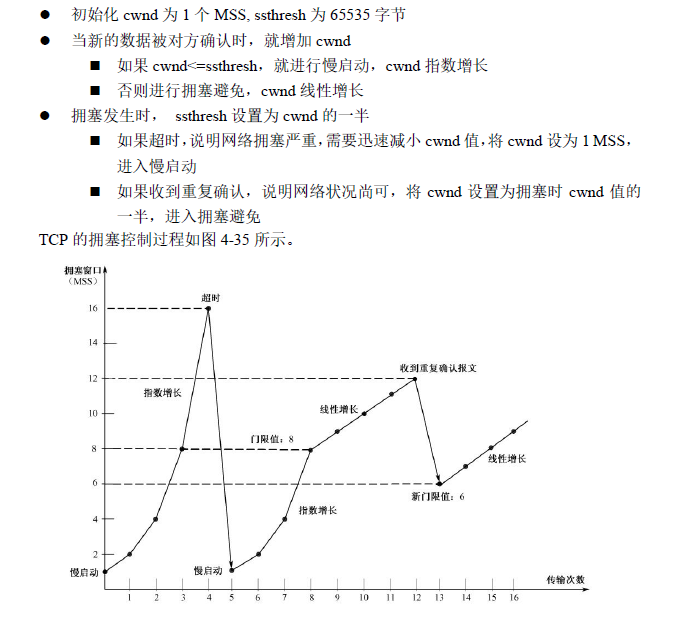
TCP连接维持的一个控制变量,称为拥塞窗口cwnd(congestion window),TCP向网络注入数据的量不能超过拥塞窗口的大小。拥塞窗口大小的初始值为1个MSS。
拥塞窗口变化的基本思想
- 当网络的状况很好,每个确认报文都能及时回来时,就增大拥塞窗口,增加注入网络的数据,这样可以充分利用网络带宽。
- 如果产生了拥塞,确认报文没有及时回来,就主动减小拥塞窗口,以缓解中间网络的压力。
拥塞窗口大小如何变化
- 慢启动算法
拥塞窗口初始值为1MSS(最大报文段长度),每经过1个RTT,拥塞窗口cwnd加倍。
- 拥塞避免算法
拥塞窗口cwnd达到门限值ssthresh后,每个RTT,拥塞窗口最多增加一个MSS。
- 门限值(ssthresh)
门限值 ssthresh是一个动态变化的值,用来确定当前采用慢启动还是拥塞避免算法。
拥塞窗口cwnd<ssthresh时,采用慢启动算法
拥塞窗口cwnd>=ssthresh时,采用拥塞避免算法
门限值初值为65535字节,发生拥塞(收到重复确认或超时),门限值降为发生拥塞时拥塞窗口的一半。
拥塞控制