MySQL索引
MySQL索引的建立对于MySQL的高效运行是很重要的,索引可以大大提高MySQL的检索速度。创建索引时,需要确保该索引是应用在SQL 查询语句的条件(一般作为 WHERE 子句的条件)。实际上,索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录。但过多的使用索引将会造成滥用。因此索引也会有它的缺点:虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件。建立索引会占用磁盘空间的索引文件。
索引的重要性
从MySQL数据库中查找书籍,就类似于从图书馆找书,如果书比较少,那么查找的速度会比较快,如果书比较多的时候,那么查找的速度就会非常的慢。这个时候图书的分类管理就显得非常重要了,图书分类管理就类似于索引(或者理解成给所有的图书设定目录)。
普通索引
最基本的索引,它没有任何限制。
创建
CREATE INDEX indexName ON mytable(username(length));
如果是CHAR,VARCHAR类型,length可以小于字段实际长度;如果是BLOB和TEXT类型,必须指定 length。
修改表结构(添加索引)
ALTER table tableName ADD INDEX indexName(columnName)
删除
DROP INDEX [indexName] ON mytable;
唯一索引
索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。
创建
CREATE UNIQUE INDEX indexName ON mytable(username(length))
修改表结构(添加索引)
ALTER table mytable ADD UNIQUE [indexName] (username(length))
索引的本质
在没有索引的情况下,为什么查询的速度会比较慢呢?
因为数据都是存储在磁盘上的,那么再执行sql语句的时候,一定会去磁盘上读取相关的数据,那就会产生磁盘IO。如果没有索引,那么会进行多次磁盘的IO操作,比较耗费时间。
为什么要使用索引?
其目的就是为了减少磁盘的IO操作,这样就可以提高查询数据的速度。
索引本质是什么?
索引是帮助快速检索出数据的数据结构。
索引的作用是快速检索出数据。
索引的本质就是一种数据结构。也就是说你创建了一个索引,其实MySQL的数据库会帮你创建一个数据结构,然后使用该数据结构来存储数据,该数据结构就是索引。
索引底层数据结构
二叉树
二叉树是一颗相对平衡的有序二叉树,对其进行插入,查找,删除等操作性能都比较好。
特点:它的左子节点的值比父节点的值要小,右节点的值要比父节点的大。
二叉树的优点:可以优化磁盘IO的次数。节点存在有顺序,可以进行范围的查询。
二叉树的缺点:插入数据的速度会比较慢,因为会更改数据结构。不平衡的问题,会产生倾斜的二叉树。
完全平衡二叉树
插入数据会平衡,但是插入的时候会改变树的结构。插入的数据的时候比较慢。而且树的层级会变高,会增加磁盘IO的次数。
二叉树是有顺序的,范围查找都是支持的。
B树
B树或者B+树的节点可以存储多个数据,所以相对于完全平衡二叉树的高度肯定会低,那么就会降低磁盘IO的次数。
B+树
B+树相对于B树有数据的冗余,叶子节点中的数据是有顺序的。那么再进行顺序查找的时候就非常的方便,只要在叶子节点顺序向后遍历即可。
MySQL索引是如何存储数据的
MySQL中是如何使用B+树的
MySQL中Innodb和myisam存储引擎默认都是使用B+树数据结构做索引的,存储的数据结构如下
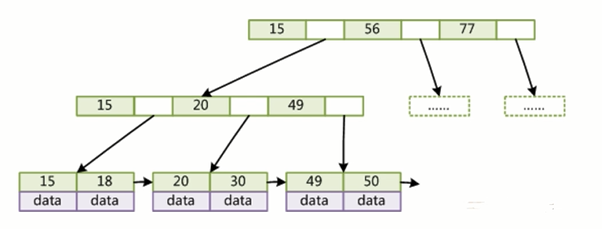
为什么只有叶子节点会存储数据,而非叶子节点不存储数据呢?
局部性原理:当一个数据被用到时,其附近的数据也可能被使用,所以操作系统为了提高效率,读取数据的时候往往不是严格按需读取,而是每次都会预读,即使只需要一个字节,操作系统也会从这个位置开始,顺序向后读取一定长度的数据放入内存中,这里的长度叫做页。也就是计算机操作系统操作磁盘的基本单位,一般操作系统中一页的大小为 4kb。
在MySQL中可以使用如下的命令查看Innodb引擎页的默认大小
SHOW GLOBAL STATUS LIKE ‘Innodb_page_size’
MySQL的页的大小默认是16kb,B+数的设计非常适合读取数据。
如果节点又存储数据和索引,数据比较多,索引就比较少,那么树的高度就越高。导致磁盘IO变多,效率变低。
叶子节点可以存储多少数据
一个节点能存储16KB的数据,这是MySQL默认的节点大小,一页16KB。
假设一行记录的大小为1kb(其实已经比较大了)
那么一个叶子节点就能存储16条数据。
非叶子节点里面存储的是索引的值和指针,MySQL默认的索引值大小是8B,指针大小是6B,合在一起是14B。那么非叶子节点可以存储的索引+指针的个数为:
161024/14 = 1170 个
那么如果数的高度是2层,叶子节点的个数也就是 1170个,那么可以存储的数据条数为:1170 16 = 18720条。
如果树的高度是3层,那每个叶子节点可以存储的条数为:1170117016= 21902400条
myisam引擎存储结构
可以使用命令创建一张新的表结构,使用myisam引擎来创建。myisam引擎的索引采用的非聚集索引,索引和表数据是分开存储的。
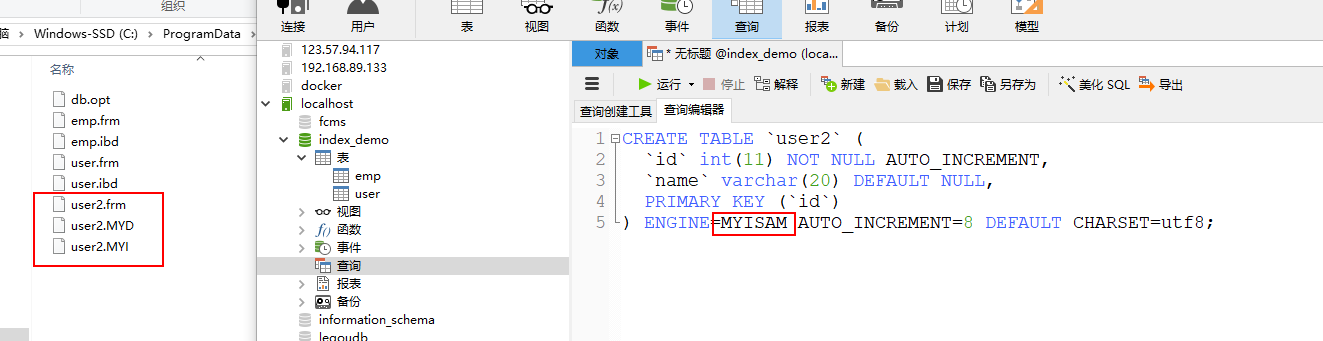
user2.frm文件是创建表的文件
user2.MYD文件是表的数据文件
user2.MYI文件是索引文件
myisam引擎的索引结构图
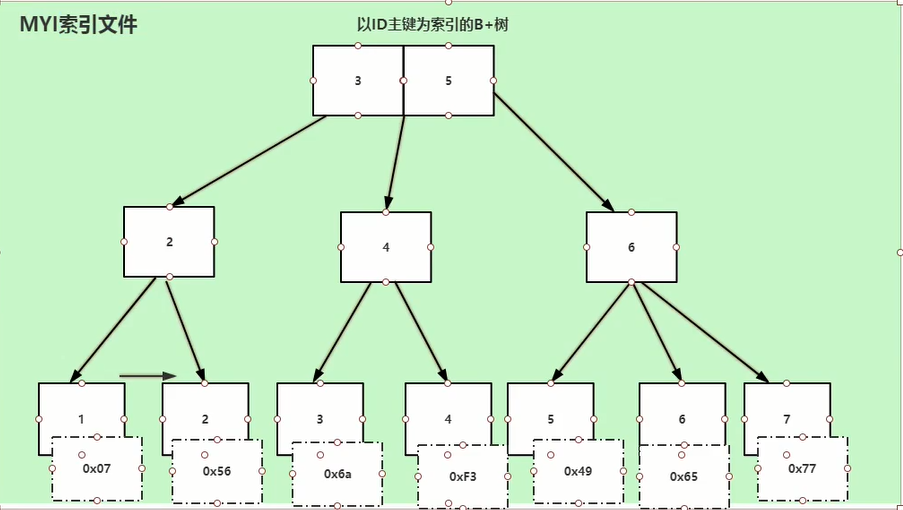
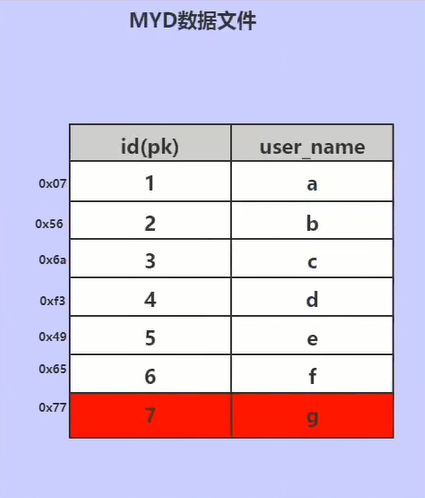
myisam引擎通过索引查找数据的时候,通过索引值找到对应的地址,通过地址找到数据。如果已name字段设置索引,效果是一样的。
Innodb引擎存储结构
数据文件user.frm和user.ibd
user.frm是创建表的文件
user.ibd是数据+索引文件
索引Innodb引擎是聚集索引,索引和数据文件在一起的。
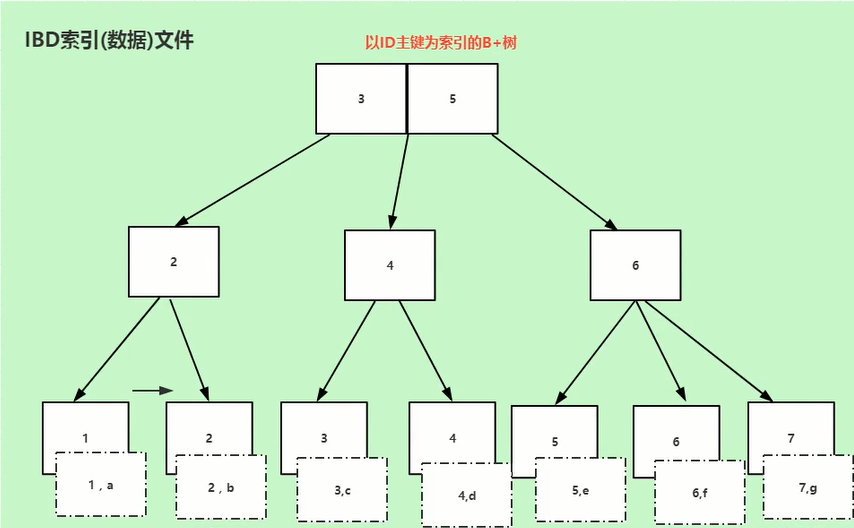
如果已name字段设置索引,那就是二级索引(辅助索引)。叶子节点中存储的该列的数据和主键值,也就意味着还需要再通过主键去查找一次数据。
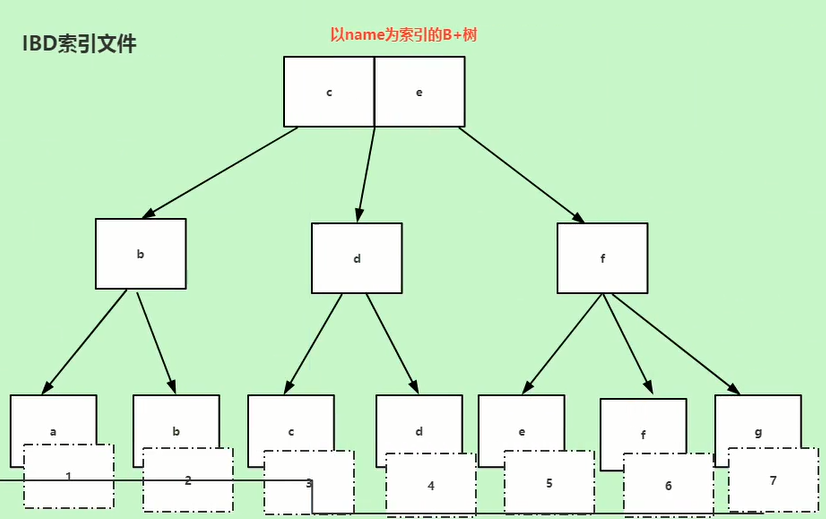
补充
数据库中最常见的慢查询优化方式是什么?
加索引
为什么加索引能优化慢查询?
因为索引是一种优化查询的数据结构,比如MySQL中的索引是用B+树实现的。而B+树就是一种数据结构,可以利用索引快速查找数据。所以能优化查询。
哪些数据结构可以提高查询速度?
哈希表 完全平衡二叉树 B树 B+树等
InnoDB聚集索引和普通索引有什么差异?
InnoDB聚集索引的叶子节点存储行记录,因此, InnoDB必须要有,且只有一个聚集索引:
- 如果表定义了PK,则PK就是聚集索引;
- 如果表没有定义PK,则第一个not NULL unique列是聚集索引;
- 否则,InnoDB会创建一个隐藏的row-id作为聚集索引;
为什么有的字段建立索引,查询速度反而变慢了呢?
列的散列度越低,不推荐建立索引。
散列度公式:count(distinct(column_name)) / count(*)
现在有一列字段,假如列的名称是 sex性别,存储的值是 男或者女,表中有500w条数据,现在执行sql:select * from t_user where sex = '男' 查询花费的时间2秒多,现在对sex 列建立了索引,再执行之前的sql语句,但是花费的时间变成了 20多秒。
在什么字段上创建索引?
where、join、 order by
索引个数不要过度,散列度低的字段,不要建立索引,随机无序或频繁更新的值,不适合作为主键,创建符合索引时避免冗余索引。
联合索引,最左匹配原则
必须从联合索引的第一个字段开始,不能跳过,不能中断。
两个字段一般是同时出现的,推荐建立联合索引,例如高考成绩查询:身份证号+考号
CREATE INDEX index_name_sex on t_user (name,sex)
EXPLAIN SELECT * from t_user where name = 'name4999008' and sex = '男'
EXPLAIN SELECT * from t_user where sex = '男' and name = 'name4999008'
EXPLAIN SELECT * from t_user where name = 'name4999008'
EXPLAIN SELECT * from t_user where sex = '男'
第四条不会应用上该索引,其余三条都可以(第二条MySQL优化器)。

